Ich bin Hans.
Im März 2010 habe ich Technikblog ins Leben gerufen. Seither blogge ich über technische Themen die mich faszinieren und im Alltag begleiten. Das sind Themen wie Gadgets, Smart Home, Elektroautos, Erneuerbare Energien und vieles mehr...






Vor einiger Zeit habe ich nach einem Workaround für ein papierloses Büro mittels OCR Scan und Netzwerkspeicher gesucht. Richtig glücklich wurde ich bisher mit keiner Lösung, aber mittlerweile habe ich eine Variante die mich zufrieden stellt. Wie ich das mittels meines neuen Multifunktionsgeräts und meiner Synology Diskstation 1019+ eingerichtet habe, erkläre ich in diesem Beitrag. Zuerst aber nochmals meine Anforderungen, weil zahlreiche Inputs immer von anderen Grundvoraussetzungen ausgingen.
Für mich ist wichtig, dass ich Korrespondenz auf Papier einfach und jederzeit einscannen kann. Ob das Rechnungen, Lieferscheine, Arztdokumente oder andere Infos sind, einfach alles einscannen und ablegen. Da ich zwischendurch einen Drucker brauche, soll das von einem Multifunktionsgerät erledigt werden können und nicht noch ein separater Scanner. Zwingend ist dabei, dass kein Computer / Mac benötigt wird. Der Scan soll direkt auf der Synology Diskstation abgelegt werden. Dort hätte ich gerne das die Scans einem OCR Workflow durchlaufen und damit durchsuchbar werden. Am liebsten gleich nach Inhaltskriterien umbenannt und sortiert werden. Schlussendlich sollen alle Dokumente per Volltextsuche auffindbar sein.

Meine Datenablage für OCR Scanning: Synology Diskstation
Bei meinem alten Multifunktionsdrucker waren alle Toner durch und ich konnte gerade zum Schnäppchenpreis ein neues Gerät aus der Börse von Arbeitgeber kaufen. Dafür habe ich mich dann schnell entschieden, da dieser Scanner auch Duplex beherrscht. Perfekt also für mein Vorhaben, das Gerät nennt sich übrigens Canon i-SENSYS MF734Cdw. Nun so einfach war dann doch nicht alles, ich brauchte nämlich einige Abende um das Scannen direkt auf ein Netzwerklaufwerk einzurichten. Wer da auch mal Probleme hat, gibt die IP-Adresse der Diskstation ein und macht einen separaten User der nur Zugriff auf eure Scan-Ablage hat und nehmt ein einfaches Kennwort. Mittlerweile funktioniert es aber einwandfrei, ich kann jederzeit scannen, unabhängig ob der iMac gerade an ist oder nicht. Genau so muss es sein.
Mit diesem Thema habe ich mich lange herumgeschlagen, tollerweise aber konnte ich das mit dem neuen Drucker umgehen. Der kann nämlich selbst PDFs direkt mit Texterkennung durchlaufen lassen und sie abspeichern. Das muss nur in den Einstellungen aktiviert werden, damit kommen die PDFs mit OCR direkt auf der Synology an.
Die meisten von euch werden diese Funktion nicht haben, auch da gibt es Abhilfe. Einerseits bin ich auf dieses Script gestossen, dass zu funktionieren scheint. Andererseits gibt es synOCR, das ist für weniger versierte User mit einer graphischen Oberfläche.

Synology Drive – Dokumente indexieren
Nun habe ich also die Dokumente als durchsuchbare PDFs auf der Synology Diskstation. Soweit so gut, am liebsten wäre mir nun ein automatisches Renaming anhand von vorhandenen Inhalten. Soweit bin ich aber noch nicht, bzw. ich habe noch keine einfache Lösung gefunden.
Wichtiger ist mir aber, dass die Dokumente indexiert werden und durchsuchbar sind. Würde ich die eingescannten Dokumente lokal auf dem iMac speichern, könnte ich einfach per Spotlight suchen und würde Inhalte finden. Auf der Synology geht das so nicht, dachte ich zumindest. Denn mit «Synology Drive» ist das nämlich möglich, wenn die Option wie im obigen Screenshot gezeigt aktiviert wird. Der Scan-Folder habe ich als Team-Ordner ins Synology Drive gezogen und nun kann jeder User meines NAS auf dem Synology Drive nach eingescannten Dokumenten suchen.
Wie das aussieht zeigt der Screenshot unten. Ich habe eine Auftragsbestätigung eines Handwerkers eingescannt, das Dokument selbst hat einfach den kryptischen Namen, welcher der Scanner vergibt behalten. Suche ich aber im Synology Drive nach Auftragsbestätigung, wird das Dokument anhand des indexierten Inhalts gefunden. Perfekt, genau was ich suchte!
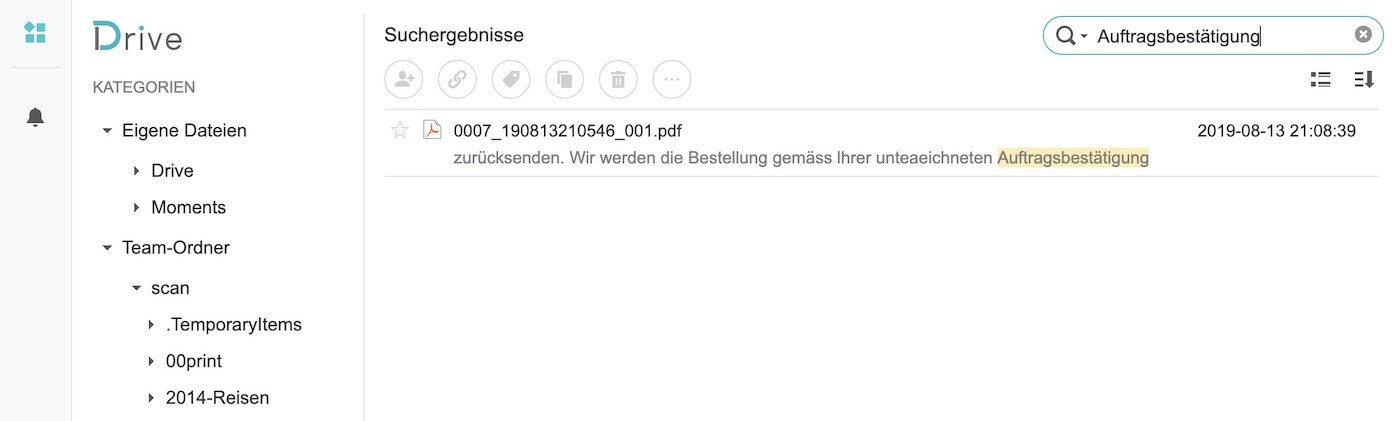
Synology Drive – OCR Suche
Nach langem hin und her habe ich jetzt einen Workaround der für mich funktioniert. Die Dokumente werden eingescannt, OCR Layer darüber gelegt, auf der Synology Diskstation gespeichert und sind indexiert. Damit sind 90% meiner Anforderungen gedeckt, die letzten 10% wären das automatische Umbenennen und verschieben in entsprechende Ordner. Vielleicht hat da der eine oder andere Leser noch gute Inputs, bin da ganz offen.
Die nächsten Schritte sind nun klar, ich werde versuchen so viel wie möglich auf Papier zu verzichten und das Büro möglichst papierlos zu betreiben. Den perfekten Workflow für Fotos von Systemkamera und mehreren Smartphone-Kameras im Haushalt wird dann das nächste Thema sein….
Im März 2010 habe ich Technikblog ins Leben gerufen. Seither blogge ich über technische Themen die mich faszinieren und im Alltag begleiten. Das sind Themen wie Gadgets, Smart Home, Elektroautos, Erneuerbare Energien und vieles mehr...





